张登友,张登友的博客,张登友的网站——
代码如下
import requests
import re
import json
import urllib.parse
from tqdm import tqdm
import time
headers ={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'
}
def get_picSrc(page):
url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17108079906974233315_1576410038567&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1576410754875'.format(str(page))
response = requests.get(url,headers=headers)
if response.status_code ==200:
# print(response.text)
temp = re.search('jQuery\d+_\d+\((.*?)\)',response.text,re.S)
if temp:
data = json.loads(temp.group(1))
data_list = data['List']
for item in data_list:
sProdName = urllib.parse.unquote(item['sProdName'])
sProdImgNo_8 = urllib.parse.unquote(item['sProdImgNo_8'])
pic_src = sProdImgNo_8[:-3]+'0'
pic_info ={
'sProdName':sProdName,
'pic_src':pic_src
}
yield pic_info
def downloadFILE(url,name):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
resp = requests.get(url=url,stream=True,headers=headers)
content_size = int(int(resp.headers['Content-Length'])/1024)
with open(name, "wb") as f:
print("Pkg total size is:",content_size,'k,start...')
for data in tqdm(iterable=resp.iter_content(1024),total=content_size,unit='k',desc=name):
f.write(data)
print(name , "download finished!")
if __name__ == "__main__":
for page in range(0,20):
print('[info] page:',page)
pic_infos = get_picSrc(page)
for pic_info in pic_infos:
print(pic_info)
try:
downloadFILE(pic_info['pic_src'],pic_info['sProdName']+'.jpg')
except:
continue
time.sleep(3)在这个路径下打开终端运行 ,记得在文件夹中运行 ( 否则被图片铺满桌面 ) 代码中sProdImgNo_8的部分改成sProdImgNo_6就可以下载1920*1080格式的了, 1到8分别是不同尺寸的,但左上还是有王者荣耀的水印,没有水印的是爬取英雄资料的背景图片是1920*822格式了。
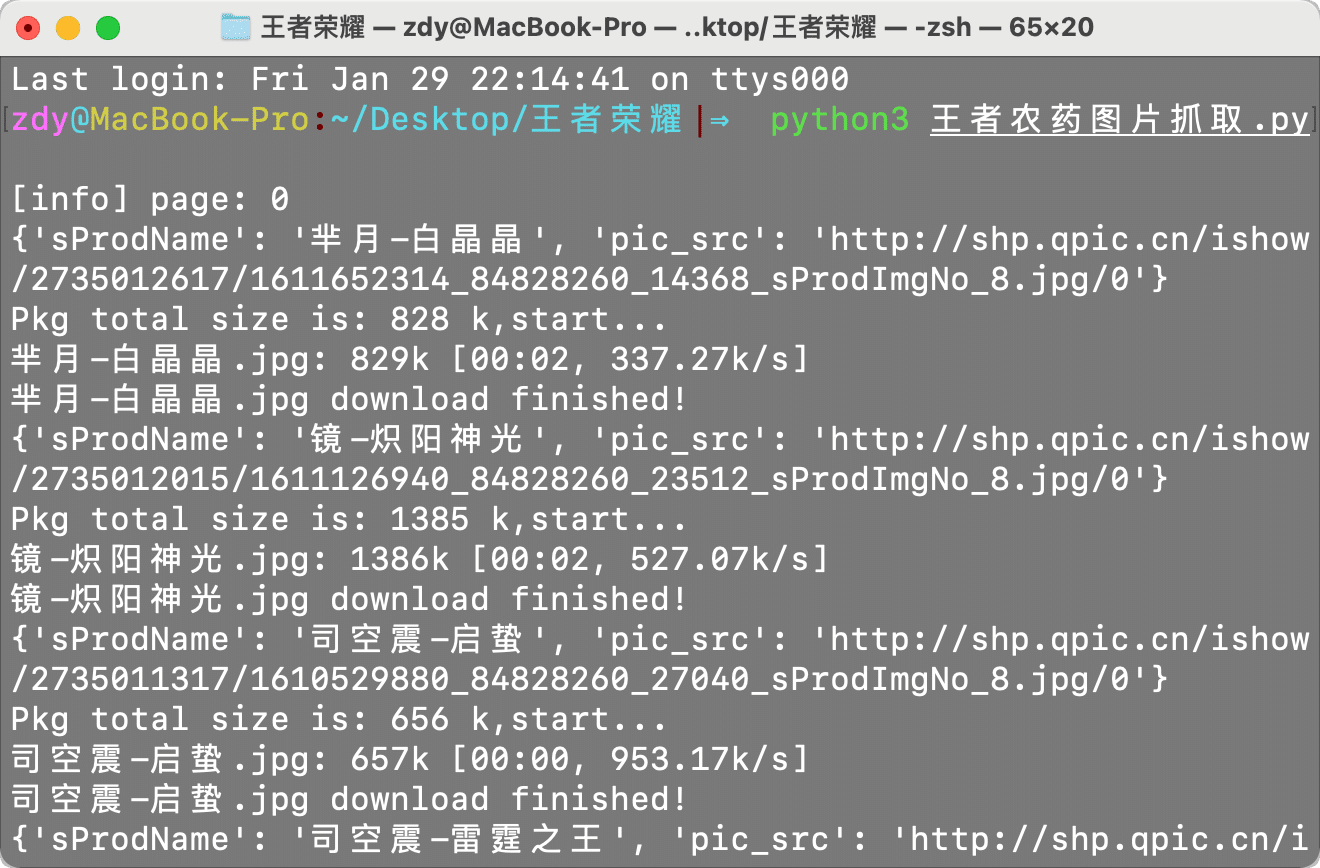
查看结果
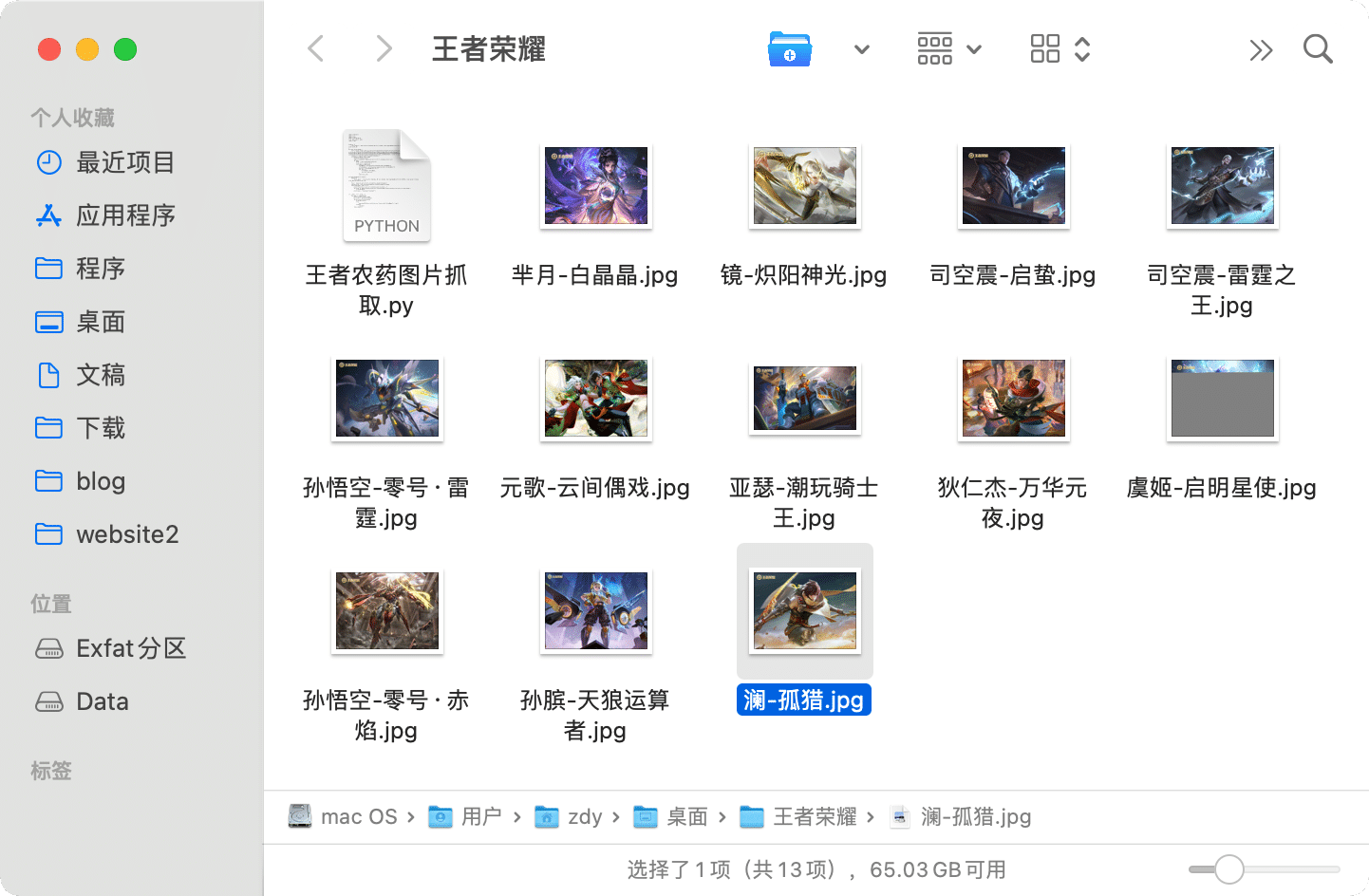
转载自一个论坛的大佬。当时下载完,过了几天才测试,忘了链接。。。。